


Last winter I built a tiny web scraper to pull competitor blog posts for a quick content analysis… and immediately got humbled. My “top keywords” were basically stopwords wearing a fake mustache. That was the moment I stopped treating keyword extraction like a checkbox and started treating it like a small craft: text preprocessing, candidate keywords, and a method that matches the job (SEO optimization vs semantic search).
1) The time my ‘keywords’ were just… “the”
I once ran frequency counts on document text web scraper and my “top keywords” were: the, and, to . Not exactly content analysis gold.
That’s what happens with zero preprocessing: no cleanup, no stopword filtering, and no clue that multi word phrases matter. Real keyword extraction identifies the most relevant words or phrases from text documents—the handles you grab later. It isn’t summarization or topic modeling.
I use it for SEO briefs, internal search tuning, and tagging a library.
Gut-check: if your top keywords sound like filler, your pipeline is broken.
Airport test: would I say this phrase to find the article later?
“There is no such thing as ‘just text’—what you keep and what you throw away changes what your system can learn.” — Emily M. Bender
2) Text Preprocessing: the unglamorous hero
Text Preprocessing is my make-or-break step: lowercase, punctuation cleanup, normalize whitespace—boring but effective. It shapes frequency analysis , TF-IDF scores, and even downstream graph based ranking like TextRank (one of several unsupervised methods, alongside statistical and embedding-based approaches).
Christopher D. Manning: “In NLP, simple baselines are strong—because text is noisy and the world is messier than our models.”
Stopword Filtering : customizable—industry terms can look like stopwords.
Lemmatize vs stem: I pick lemmatization for readable SEO multi word phrases.
Scraped pages: remove nav menus, cookie banners, repeated footer text—classic data contamination .
YAKE multilingual: set language, keep accents, watch tokenization.
Confession: I still forget boilerplate sometimes—and it always bites me.
3) Candidate Keywords: where POS Tagging earns its rent
I don’t trust raw n-grams alone—you get “of the” and other junky fragments. This is where Candidate Keywords selection bridges preprocessing and scoring ( RAKE scoring , TF-IDF method, TextRank algorithm ) by cutting noise before any relevance score.
POS Tagging ( Part Of Speech ) is my filter: with a spaCy Model , I keep nouns, proper nouns, and adjectives.
Named Entity pass: people, products, places—often SEO gold.
Multi-word phrases matter: “semantic search,” not just “semantic.”
Matthew Honnibal: “Parsing and tagging aren’t academic luxuries—they’re practical shortcuts to structure in messy text.”
Rule of thumb: if it’s hard to type as a query, it’s not a good candidate.
4) Scoring the obvious: Frequency Analysis, TF‑IDF, and RAKE
Frequency Analysis & Statistical Methods
Frequency analysis is my fastest statistical methods win for internal tagging—and the fastest way to get fooled by repeated fluff. Plain term frequency loves “great” and “nice.”
Term Frequency vs TF‑IDF Method (needs a corpus)
With a corpus, the TF‑IDF method downranks words common across documents; it measures term importance relative to document corpus frequency.
Karen Spärck Jones: “Computing relevance is the art of deciding what matters—TF‑IDF was one early, useful way to do that.”
RAKE Scoring
RAKE scoring boosts phrases via frequency and co-occurrence with nearby words, so “battery life” can beat “battery.” Reviews vs papers: same pipeline, different winners. I sanity-check by sampling 10 outputs: “Would a reader click this?” Sometimes the best keyword is the one my editor hates—but users type.
5) Graph-Based magic: TextRank Algorithm (and when it’s not magic)
My mental model: I turn candidate words/phrases into a Graph Based network, then rank what’s central. The TextRank algorithm uses graph-based ranking to pick top keywords for keyword extraction —it feels “smart” because it rewards terms that connect multiple ideas.
Rada Mihalcea: “Graph-based ranking lets you reuse a powerful idea: importance emerges from connections, not just counts.”
Struggles: very short pages, repetitive pages, boilerplate-heavy text.
My tweak: run TextRank after preprocessing + POS filtering, so the graph isn’t noise.
SEO: great for editorial phrases that read well in headings.
Unpopular opinion: if I can’t explain my graph, I don’t trust the keyword score or output.

6) The semantic leap: KeyBERT, BERT Embeddings, and Cosine Similarity
What changed for me: embedding-based keyword extraction catches meaning, not just repetition—perfect when frequency analysis fails due to paraphrasing.
The KeyBERT method is simple: create BERT embeddings for the document and candidate phrases, then rank them by cosine similarity to get a relevance score for semantic search SEO.
Jacob Devlin: “Deep contextual representations let us model meaning in a way count-based features never fully could.”
Shines: jargon-heavy specs, synonyms, niche terms.
Hurts: speed, hardware, and over-trusting Transformer Models and Language Models .
Newer transformer-based models like JointKPE and Diff-KPE push keyphrase extraction further. My quick test: if my boss asked “what’s this about?”, would these keywords save me?
7) YAKE Algorithm + Spark NLP : when you need scale (or multilingual)
The YAKE algorithm is my go-to for fast keyword extraction from a single document. It leans on statistical features (not a big corpus), so in NLP python audits it often beats naive frequency lists—especially on multilingual text.
When I need this to run nightly, I jump to the John Snow Labs Spark NLP ecosystem. The YakeKeywordExtraction annotator gives practical knobs like n-gram size and top-k, so I can tune without drama.
Javed Ahmed: “In production NLP, the winning model is often the one you can monitor, tune, and rerun without drama.”
Scaling is easy; debugging weird keywords at scale is the real job.
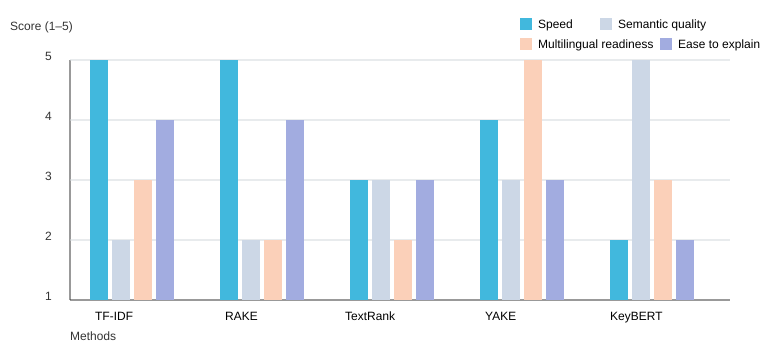
8) Picking a method (without overthinking it) + mini comparison chart
My keyword extractor cheat-sheet: corpus → TF‑IDF method ; readability → TextRank algorithm ; semantics → KeyBERT method ; single-doc speed → YAKE algorithm / RAKE . These are unsupervised: statistical, graph-based, and embedding-based. For SEO optimization , I chase phrases people type; for semantic search SEO , I chase intent. Cindy Krum says,
“SEO isn’t about chasing words; it’s about matching meaning—and then proving it with what people actually search.”
My pipeline: preprocess → POS tagging → run 2 methods → blend/dedupe by relevance score. I sample 3 pages and track “keeper rate.” TF‑IDF is my microscope; KeyBERT is my compass—after my editor asked for “keywords that don’t sound like a robot.”

9) Conclusion: my ‘keyword extraction’ litmus test
The real win in my Python keyword extraction wasn’t a fancier model—it was respecting the workflow. Since keyword extraction identifies the most relevant words or phrases in a document, my litmus test is simple: can I explain why we extract keywords—candidate, score, and context—so it holds up in semantic search?
“Don’t optimize for tools—optimize for humans, and measure the outcome honestly.” — Avinash Kaushik
Remember: outputs are suggestions, not commandments. For social media, I turn keywords into hooks, not hashtags-only spam. Next, I’ll blend KeyBERT with TextRank and track keeper rate. Pick one method this week and run it on a page you know well—your instincts sharpen fast.
References :
https://cbdhealhub.com/mastering-esports-betting-singapore-essential-guide-for/
https://cbdhealthbud.com/masterful-esports-betting-singapore-guide-for-gamers/
https://cbdjuiceshop.com/mastering-esports-betting-singapore-a-complete-guide/
https://cbdsupplyhub.com/expert-guide-to-esports-betting-singapore-essential/
https://cloudhavencbds.com/masterful-guide-to-esports-betting-singapore-key/
https://earthbloomcbd.com/essential-guide-to-esports-betting-singapore-strategies/
https://freshcbdmart.com/mastering-esports-betting-singapore-comprehensive-guide-for/
https://greencbdherb.com/masterful-esports-betting-singapore-2026-complete-guide/
https://livecbdfoods.com/mastering-esports-betting-singapore-expert-guide-for/
https://vitalherbcannabis.com/mastering-esports-betting-singapore-essential-guide-for/
https://glowleafdispensary.com/mastering-esports-betting-singapore-comprehensive-guide-for/
https://thezencbdstore.com/masterful-guide-to-esports-betting-singapore-in/
https://purewavecbd.com/mastering-esports-betting-singapore-a-complete-guide/
https://goldenherbcannabis.com/mastering-esports-betting-singapore-2026s-essential-guide/
https://mysticherbdispensary.com/expert-guide-to-esports-betting-singapore-in/
